Nell’evento del 24 Ottobre 2023, organizzato da AIDA (Artificial Ingelligence Doctoral Academy), dal titolo “The Unreasonable effectiveness of Large Language-Vision Models for Vodeo Domain Adaptation”, la professoressa Ricci ha parlato delle attività di analisi video, come il riconoscimento delle azioni, sono state a lungo oggetto di studio nella visione artificiale. Nell’ultimo decennio si sono compiuti progressi significativi con lo sviluppo di architetture specializzate basate su reti neurali profonde, come le reti neurali convoluzionali tridimensionali (3D CNNs) e i Video Transformers, addestrati su set di dati annotati su larga scala. Tuttavia, ottenere video di addestramento etichettati a sufficienza per scenari del mondo reale può risultare molto costoso e richiedere molto tempo.
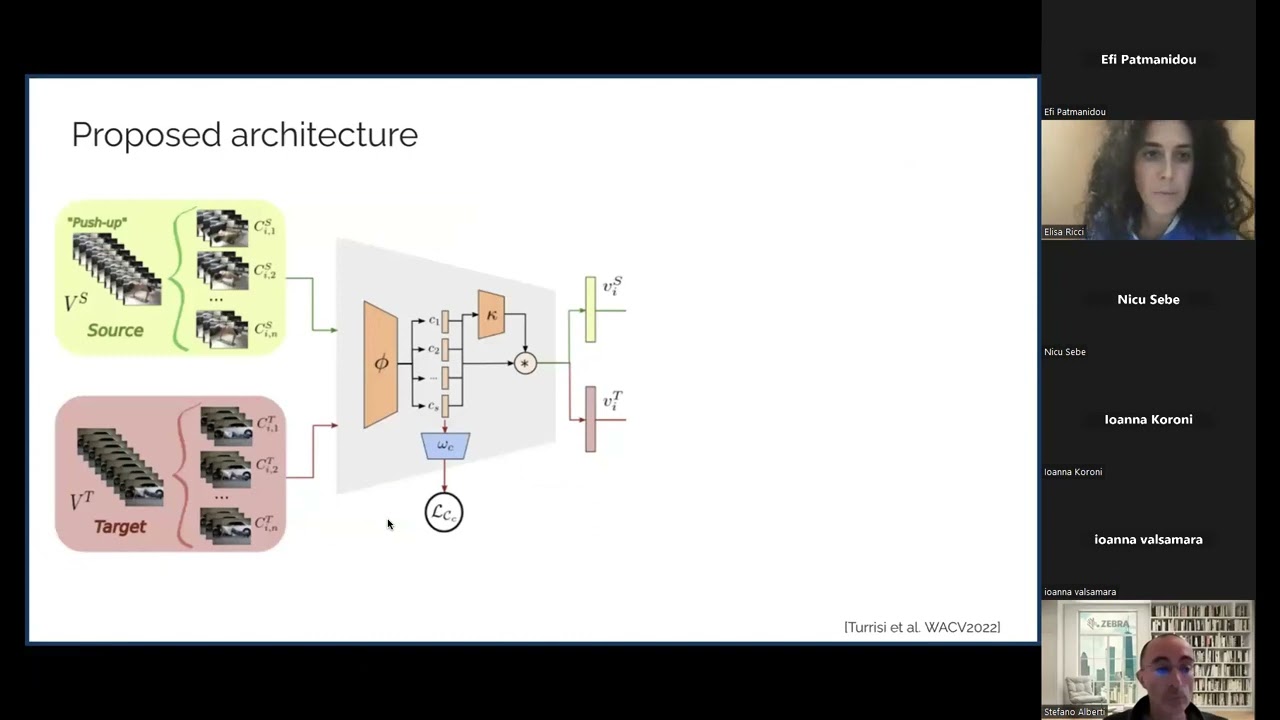
Per alleviare l’onere dell’annotazione di set di dati su larga scala, sono stati introdotti metodi di Adattamento Non Supervisionato basati su Video (VUDA). Questi metodi VUDA si basano sull’idea comune di trasferire conoscenze da un dominio di origine etichettato a un dominio di destinazione non etichettato.
Negli ultimi anni, il campo della visione artificiale ha anche visto l’emergere di una nuova generazione di potenti architetture basate su reti neurali profonde, addestrate su set di dati immagine-testo su scala internet. Questi modelli, comunemente noti come modelli fondamentali o Large Language Vision Models (LLVMs), hanno raggiunto prestazioni eccezionali e sono diventati un pilastro della ricerca moderna in visione artificiale. In questa presentazione, introdurrò i lavori recenti del mio gruppo di ricerca che sfruttano gli LLVM per affrontare le principali sfide del VUDA.
Di seguito si può trovare il video dell’evento: